
- Today
- Total
프로그래밍 농장
Embedded System 본문
File의 종류
Text file / Source file / Executable file . .
File attribute (파일의 구성요소)
-> Name : 사람이 알아보도록한것
-> Identifier : 컴퓨터 시스템상에서 알아보도록한것
-> Type : os가 생각하는 타입 ( regular type , link , .. 등 )
-> Location : device상에 위치한곳
-> Size : 파일의 사이즈
-> Protection : 퍼미션(권한) R ,W, X
-> Time, data and user identification
File Operations (파일 동작)
-> Create
-> Write
-> Read
-> Reposition within file
-> Delete
-> Truncate : file 껍데기만 남기고 실질적인내용을 전부 지움
-> Open : 모든 파일은 디렉토리내에 존재하며, 디렉토리내에서 검색을하여 오픈함. -> 없으면 에러 -> 있으면 찾은 파일을 메모리에 옮긴다. ( cpu는 모든정보를 메모리와 소통 )
-> Close : 메모리에 있는 내용을 다시 디스크에 옮겨놓는것 . ( if, 수정사항이 없을경우 굳이 디스크에 넣을필요없음 )
Open Files
-> open file table : 열려있는 파일들을 추적하는 일종의 테이블 ( 파일이 몇번 열렸나까지 추적 )
File-open count : 파일을 오픈하면, 오픈파일테이블에 없을시 그 테이블에 기록. 이후에 그 파일을 누군가 또 열려고하면, 그파일을 직접찾아서 오픈하는것이아니라, 오픈파일테이블 내의 값을 가져다 씀.
-> 그렇다면 언제 등록이 해제되는지? : 열떄마다 카운트를 하나씩 증가, close할떄마다 하나씩 지움 -> 결국 카운트가 0이되어서, 어떤프로세스도 참조하지않으면, 그떄 오픈파일테이블에서 등록을 해제함
File Locking
-> File도 공유자원이기때문에, 내가 파일을 열때 lock을 걸어놓음으로서, 다른 프로세스가 접근하지못하도록 하는것이다.
-> 그러나, 모든경우는 아니다. 만약 파일을 read only (읽기전용)으로 열떄는 여러개의 파일이 다 열릴수있다 . ( shared lock )
파일 확장자

.a , .so -> library 파일이다.
Directory structure
: file name을 file control blocks으로 바꿔서 해석해주는 symbol table과 같은 개념 ( 단순히 파일을 모아놓은것이 아니라, 파일에 대한 구체적인 데이터를 가지고있는 파일관리 단위중 하나이다. )
-> Directory operations ( 디렉토리 연산 )
- Search for a file
- Create a file
- Delete a file
- List a directory
- Traverse the file system
File-System Structure
: 물리적으로 저장되어있는 데이터덩어리들을 우리가 생각하는 논리적인 단위의 파일로 바꿔서 편하게 파일을 조작할수있도록 해주는 인터페이스이다.
-> 핵심이되는 구조제 : FCB ( File control block ) : os는 이를 가지고 실질적으로 파일을 조작 (os가 상대하는 파일구조체)
-> Device driver : 실질적으로 파일을 ssd, 등에 기록하는 것
File system Layer
1.application programs :파일을 열거나 쓰고 싶을경우, os에 알려준다 ( user level )
-> 이후부터는 ( kernel level )에서 동작
2. os는 file open과 같은것을 받으면 logical file system을 동작시킨다.
( 3. logical file system의 기능 )
3. file open ( fopen)을 할경우, 디렉토리를 뒤져서 file name을 찾은후, 이를 file open tableㅇ[ 올려놓고, 메모리에서 파일의 정보를 올려놓은후, 사용자에게 마음대로 사용할수있도록 구조체를 넘겨준다 .이를 file number(id), file handle(파일 구조체- FILE*) 등라고하며, 이렇게 바꿔서 사용자가 사용할수있도록 File control block으로 만들어놓는다.
( 4. file-organization module의 기능)
4. 실제로 파일내용들이 메모리에 흩어져있기 떄문에 -> 만약 100번째 라인을 수정하고싶다면, 이떄 100번쨰 라인의 데이터가 어디있는지 찾아야하는데 이 역할을 file-organization이 한다. ( physical하게 변환해 주는기능)
5. 이후 실제로 접근할떄는, Basic file system에서 수행한다. ( 만약 위에서 123번쨰 block이라고 확인되었다면, 디바이스에게 위 block을 찾아오라고 명령을한다.
6. Device drivers가 위 명령을 수행한다. -> 위의 physical 123 block을 실제 해당되는 디바이스에서 읽고 쓰는 과정을 관여한다.

File System [파일시스템]
CD-ROM : ISO 9660
Unix 는 UFX,FFS 를 가진다.
Window는 FAT, FAT32, NTFS
Linux는 저널링파일시스템이라고하는 ext4가 대표적이다.
-> 요즘은 ZFS, GoogleFS 등등이 등장한다.
※ 파일 시스템이 다르면, 다른 파일 시스템에 저장된 파일을 읽을 수 없다.
FCB ( File control block )
-> 아래와 같이 file에 대한 permissions. dates,. 등이 저장되어있는것
ls에는 access가 나온다. file date에서 가장 중요한것은 만든날짜, 가장최근수정된날짜, 가장최근접근된날짜( 수정이아니어도)

--> 파일 관련 2가지 table
System-wide open-file table : 전체에 걸쳐서 오픈된 파일들을 저장하는 테이블 ( 파일 자체를 관리 )
Per-process open-file table : 특정한 프로세스가 어떤 파일을 쓰고있는데 나타내는 테이블 ( 어떤 프로세스가 어떤위치의 파일을 쓰고있는지를 가르키는 정보를 가짐 )
파일시스템(file system)의 동작과정
처음의 file을 오픈 (open() ) -> 파일의 이름을 찾아서 logical file system에 넘긴다. 이후 system-wide-open-table을 뒤져본다.
-> 만약 있는데 누군가 이미쓰고있다면 ? : per process open-file entry에 아까 찾은 system-wide-open-table에서의 위치를 저장시켜놓는다.
-> 만약 없 다면, 디렉터리구조에서 디렉터리를 전부 뒤져서 해당파일을 찾은후, 해당파일에 대한 file control block을 가지고 system-wide-open-table에 등록을 시킨다.
위와 같이 system-wide-open-table에 등록을 한 이후부터는, 파일이름은 의미가없다. file control block(FCB)의 아이디를 사용 .
Mount : -> 마운트를 해라 ~ .. : ex) usb를 꽂을시, usb와 해당 pc의 파일시스템이 다르기때문에 이를 맞추어주는것 ?
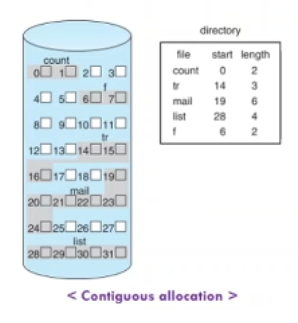
Contiguous Allocation Method (연속적으로 저장)
-> 파일을 저장할떄 구체적으로 어떻게 디바이스에 저장할것인지에 대한 방법
가장큰장점 : 디렉토리 구조가 깔끔해짐 / 물리적인 특성상 데이터를 한번에 연속으로 읽어내기에, 성능이 좋아짐
단점 : 빈공간만큼을 찾아야하는문제점 / file size를 미리알아야하는 문제점 / external fragmentation (외부단편화) : 공간이 연속적이어야하는데 중간에 끊기면 안되는문제
2. Linked Allocation Method
어차피 block과 block간의 논리적인 연결이있는것이 아닌이상,(단순히 물리적인공간) 그냥 필요한만큼 linked 해준다.
장점 : data가 끝난다음에 어떤 block으로 가야하는지 포인터가 붙어있음. --> external fragmentation(외부단편화) 문제 X ,디렉토리 구조가 깔끔함
단점 : 어떤 block으로 링크되어있는지까지 저장되어있어서 불필요한 용량을 차지함 , data가 흩어져있으면, 디스크가 이를 찾아다니면서 그만큼 시간이 더 걸림 ( 초기에는 이방식을 그래도 많이 사용함 )

3. FAT (File Allocation table)
처음에 디렉터리 구조에 파일 이름이있고 이것이 start block을 가르킨다. 이후 linked allocation에서는 block 자체에 포인터가 붙었는데, 여기서는 뒤의 포인터들을 위한 별도의 테이블들이 존재한다.
( 결국에는 포인터들만을 모아놓은 테이블이 존재한다는 뜻이다. )
단점 : 너무많은 점프를 해야한다. 만약 데이터를 지워야할경우 포인터를 따라가면서 전부 지워야한다, 파일의 크기가 클경우, 이 테이블도 같이 커져야하기때문에 최대사용가능한 파일의 크기가 한정적이다.

4. Indexed Allocation Method
이전가지는 모든 disk안의 block은 동일한 data block이었다. 하지만, 여기서는 특정한 block은 특별한 의미를 가진다.
위의 Fat 테이블을 별도로 만드는것이아니라, 기존의 data block중 하나를 index block으로 만든후, 그안에 이 내용을 저장하는 것이다.
ex) fat의 경우 5번째 block이라고치면, 5번을 점프해야하는데, index의 경우 indexblock내의 저장된 block을 바로 참조가 가능하다. -> 이를통해 외부단편화문제도 해결이 가능하다.
단점 : 약간의 비효율성이있을수있다. block의 최소단위가 4kb라고 했을떄, 내가 만든 파일이 1kb밖에 안된다고 했을떄, 기존에는 3/4를 못쓰기에 낭비가 그정도뿐이었는데, Indexed의 경우 파일을 똑같이 생성했을때, 3/4을 낭비하는것은 낭비대로 하면서, index에서도 0만큼 사용(1개) 하므로 결과적으로는 7kb를 낭비하는꼴이다.
단점2 : block size를 정한순간 이 block에서의 최대 파일사이즈를 정해버리는 것이기 때문에 이를 초과하는 사이즈를 다룰수없다.
3. 또한, 기존의 Index의 경우 19 block이 전부 data를 가르키지만, multilevel index의 경우 index파일 내에서 index에 또 접근한다 -> 이는 훨씬 더 많은 파일을 관리할수있지만, (최소 제곱) -> 그만큼 공간낭비는 더 커진다.

--> 위와 같은 Indexed allocation의 문제를 해결하기위한 방법으로 아래의 combined가 나왔다.
Combined Scheme for Allocation Method
무조건 하나의 Scheme을 적용하는것이 아니라, 파일의 상태를 보는것이다.
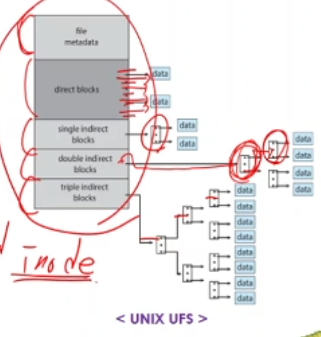
파일에 대한 모든 data의 출발점 : inode 라고하며, 대부분의 UNIX계열의 시스템은 이와같이 구성되어있다.
small data를 저장하는 파일을 위해서 direct block들을 저장하는 공간이있다.
만약, level을 하나더 늘려야할것같을시, single indirect blocks를 추가하여 index - index로 연결되는 index block이 존재한다.
위에서 또 부족하면, double indirect blocks를 생성해서 두번더 index block에 접근한다.
( data 량이 커질수록 위와같이 여러번 접근하는 구조를 생성한다. ( 유동적으로 ))
유닉스(UNIX) 계열에서 유명한 두가지 file system
1. EXT4
- EXT4 ( journaling file system ) : 고장에 강한 시스템 . 미리 파일을 쓰기전에 log와 같은것을 기록해놓아서 중간에 문제가 생겨도 복구가 용이함.
- Super Block : 파일시스템의 핵심이되는 block으로서, inode도 관리하는등의 작업을 수행한다.
2. FAT ( File Allocation Table )
- 과거부터 쓰던것 최대 4gb를 넘지못함 ( usb .. )
- 이를 극복하기 위해 윈도우계열에서 나온것이 NTFS이다. 16TB이며, 드라이브에서 256TB까지 지원한다고한다.
파일에 대한 정보를 얻는 시스템콜 : stat ()

permission에 대한 설정 : chmod ()로 시스템콜에서 지원해줌
S_ISUID : set user id : 다른사람의 권한으로 잠깐 수행해줌
모든 권한을 세팅할수있는 상태로 만들기 위해서는 아래와 같이 owner로서 S_IRUSR | S_IWUSR | S_IXUSR 세가지를 and로 묶어 실행해주면된다.

current working directory 를 찾는 함수 : getcwd () (절대경로기준) (pwd)

chdir () : 디렉터리의 위치를 바꿀때

mkdir () : 디렉터리를 만들떄

rmdir () :디렉터리를 삭제할때

opendir () : 아래와 같이 include를 해주고 아래 구조체를 선언한다.
디렉터리 이름과 inode 정도를 얻을수있다. ( 구조체에서 )

Hard link : 파일을 하나만드는것이다. 이미 있는 inode를 또 가르키는 파일을 만드는것 .

파일 a가 있다. a는 inode를 가지고있을것이다. 여기서 link를 만들면 a의 inode를 가르키는 파일을 또 만드는것이다. 9아래와 같이 .. 또한 다른 디렉토리에 있어도 만들수있다. )

여기서 A가 가장 먼저 만들어졌다고 해서, 다른 애들과 다르게 우선권이있다거나 하는것없이 ,a,b,c .. 전부다 동등하게 inode에 접근하는 구조이다.
inode는 위의 상황에서 본인에게 걸려있는 link count를 센다
Symbolic link vs Hard link
심볼릭링크 : a원본에 링크b를 걸고 원본을 날리면 b는 의미가 없어지는것 ( 바로가기 )
하드링크 : 원본이 없어져도 여전히 파일컨텐츠에 접근할수있는것 ( 카피와 비슷 .. 파일을 새로만든것처럼 보임 (실제는 inode에 접근 )
rename ()

- copy file
: 유닉스는 자체적으로 copy를 지원하지않는다.
copy 와 hard link 의 차이점
hard link는 inode가 하나이며, 하드링크를 걸고 같은 inode에 접근한다.
copy의 경우 새로 inode를 만들어서 접근하며, 새로만든 inode에 기존의 inode의 내용을 전부 복사한다. ( 별개라고 판단 )

파일을 copy하는 과정
1. src와 dst를 받아서, 소스파일과 데스티네이션 파일을 연다.
2. 기존의 파일이 있다면 size 0으로 만들어서 내용을 없애고,
3. read 내용을 읽어서 메모리에 올려놓고,
4. 다시 write에 위의 내용을 쓴다.
위 3,4 과정을 소스파일 size가 끝날떄까지 loop를 돌면서 계속 수행
5. 이후 전부 copy가 끝나면 소스파일과 데스티네이션 파일을 종료한다.

만약 디렉터리를 copy하려면 ? -> 디렉터리를 새로만들고, 원래 소스디렉터리에 있는 내용을 새로만든 디렉터리에 전부 copy해준다.