
- Today
- Total
프로그래밍 농장
about ARP Protocol 본문
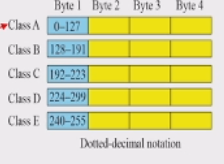
각각의 bevice identify 가능 : bit 값에 따라서 관리(manage)가 간편함
A클래스가 가질수있는 네트워크주소 : 8 bit
B클래스가 가질수있는 네트워크주소 : 16 bit
C클래스가 가질수있는 네트워크주소 : 24 bit
- 목적지주소로 사용될수있는 주소
unicast ,broadcast, multicast
- 소스주소로 사용될수있는 주소
unicast ( 특별한 주소 1개만 가능 )
모두가 0/1일떄 사용되는 주소 ( 0.0.0.0 )
all zero address / all one address
all zero address -> 매우 특수/ 제한적/ but 필수적으로 사용됨 : 처음 device 구매후 설정시 필수사용 -> host와 sever가 소통하면서 DNS, NETWORK 주소등을 설정함 . ( dhcp request ... ) -> 모든 노드가 확인가능하고싶을떄
루프백 주소( loopback address )
127 .. .
시스템내에서 소프트웨어를 test하기위해서 ( ex. 공유기 .. ) 등을 프로세스내에서 소통이 잘되는지 확인하기 위한 주소 -> 시스템 내부에서만 프로세스간 통신을 위해사용 / 네트워크로 나갈수없음
private주소( private address )
주소공간이 32bit뿐이기 때문에 -> global forward 불가능 , 로컬에서만 사용가능
network prefix (24bit만 사용)
171.16 . . / 169.254 . . / 192.168 . . : 공유기주소로 주로사용
network prefix의 마지막 주소 : directed broadcast address
public주소 (public address )
전세계적으로 가능 global forwarding 가능
목적지가 broadcast address 까지인 packet은 네트워크 내에서 모든 노드까지전달되지만, 라우터(router)를 만나는 순간 더이상 forward 되지않고 폐기한다.
->
라우터(router)에서 broadcast packet을 차단(block)하는 이유 : broadcast는 모든 노드에 발생시키기떄문에 overflow가 발생한다.
NAT : private 에 발생된 device들도 public으로 변환해주서어서, globally 하게 사용하능하게 해주는 router
-> 적은 수 에 할당이된 public에 많은 user(device)들을 수용해서 network service를 만들기 위함
-> privat주소와 public주소 사이를 mapping 해주는 기능을 함.
보통 Network를 설계할때 50-60%가 사용할것이라고 생각하고 구성. -> router의 성능이 50-60프로가 넘어가면 error 발생 : -> 내가 적은수의 public 주소를 가지고도 많은수의 user들을 service할수있다면 ? -> NAT
Packet delivery
direct delivery / indirect delivery 공존
1. direct delivery가 이루어지는 경우 : sender 와 reciever가 동일 네트워크에 존재할떄
2. 마지막 router와 destination host 사이일때
-> 라우터에서
1. packet reception 확인 (수신 패킷확인)
2. destination주소 추출 (목적지주소 추출)
3. 목적지주소와 자신의주소 비교 : 같다면(동일네트워크에 존재) direct delivery
다르다면 : indirect delivery -> 라우터들을 거쳐서 진행
Forwarding (포워딩)
목적지로의 경로 결정 후 경로상의 next node에게 패킷을 전송하는것.
- Next-hop 기반 (다음노드) forwading
전체경로 정보를 라우팅테이블에 반영 X / only next-hop 정보만 반영
-> 라우팅 테이블의 크기를 줄일수있음 (메모리사이즈를)
ex) 구글에 접속하려면 20개의 ip주소값을 가져야한다 -> 20 * 32bit -> 구글엔트리 하나에 대해서 640 bit 가 들어있어야함 -> 라우팅메모리가 커짐 : 시스템메모리가 커짐 : 시스템 단가 올라감 : 단가 올라감
한국에서 구글까지 평균 19개정도의 노드를 거친다 : 라우팅 테이블
-> 이때 Next Hop 만 저장함으로써, 효율은 그대로 유지 + 라우팅 테이블의 크기를 줄다는 장점
- Network-Specific (네트워크 주소)
host단위의 라우팅 테이블 X / network prefix 단위의 라우팅 테이블 -> 라우팅 사이즈를 줄일수있다.
searching process 를 감소시킬수있음
백본 라우팅에 사용되는 dcp프로토콜은 전부 Network=Specific 단위로 되어있음
(특정지역 , 사이트 단위 ex) 상명대 , 은평구 . . )
- Host-Specific Method (호스트 주소)
로컬 네트워크에서 사용되는 최종목적지 단의 라우팅 테이블의 구조 -> host 단위.
host-specific -> GateWay -> R
-> R
위 와 같은때, host <-> GW 사이에서 호스트 주소단위로 정하여 어떤 라우터로 향할지 결정
로컬 네트워크에서 최종전달될때 사용
- Default Method (디폴트 주소)
Default -> 만능키
Internet = best-effort 서비스
해당하는 노드에 대한 정보(라우팅 테이블)가 없음
Default entry가 정의되어있음
서브넷이 없는 address 체계에서 forwaing module이 동작하는 방식

패킷 수신 -> destination address를 추출 -> 주소 비교 (내 주소, 목적지 주소) -> 어떤 클래스인지 확인 -> 클래스에 따라 네트워크 주소 추출 -> . . . .
예제 1 ) 인터넷파트에서(class) R1라우터에서의 라우팅 테이블을 구하여라
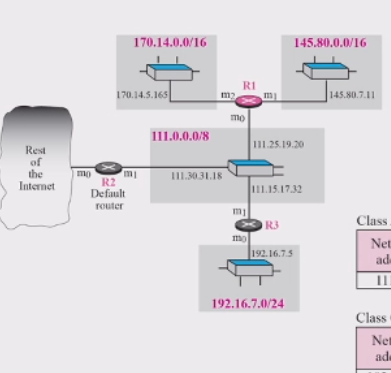
170.14.0.0/16 -> 170 = 10101010 : 10
145.80.0.0/16 -> 145 = 10010001 : 10
111.0.0.0/8 -> 111 = 01101111 : 01
192.16.7.0/24 -> 192 = 110000000 : 11
- routing(라우팅)
사전에 routing 정보를 구축하여 각 목적지로의 경로 정보를 구성
라우터의 구조 : input / output / routing processor - 세가지 단계

-> Switching fabric : 현시점 가장 비쌈
- input port : Physical layer(발생된신호 처리) -> Data link layer( 0101.. 컴퓨터신호로 변환) -> Queue
- outputport : Queue -> Data link layer( 0101.. 컴퓨터신호로 변환) -> Physical layer(발생된신호 처리)
기본적인 Switching fabric 구조 : Banyan Switch
- Flat routing : 라우터의 엔트리(entry) 갯수가 전부 동일 ( 동일레벨 ) : 소규모 구조
- Hierarchical routing : [계층적구조] : 영역을 나눈후, 같은 도메인으로 묶였을떄만 동일한 정보공유 -> 확장성이 좋음 -> 라우팅 테이블의 규모가 서로 상이하기 떄문 : 현재 모든 네트워크의 기본 구조
- Geographical routing : [위치,지리적 라우팅] : ex) GPS정보 , 특수목적으로 사용
- IP Protocol
- Unreliable & connectionless
datagram을 직접전송 : Unreliable
- Best-effort : -> not guarantee : 네트워크에서 제공가능하면 최대한 제공
- 각 datagram은 독립적으로 실행 -> ( 목적지만 보고 동작함) / out-of-order (들어온 순서대로 처리)
- layer 4
- TCP protocol : reliable 한 특성을 가짐 : out-of-order 방식해결 : 순차적처리
ICMP : port정보를 전송
- Datagram = packet : 데이터그램 : 가변성(variable)을 가짐 -> 헤더정보에 total length 들어감( 20 - 60 bytes )
- TTL (Time to live) = hop count (8 bits) : 이 datagram이 네트워크안에서 지나갈수있는 최대의 수 ( 몇개의 라우터를 거쳐갈수있는지 ) -> packet이 loop되는것을 막을수있다 . -> (최대 64번이 지나면 폐기)
= Number of hops : ip datagram이 소스로 부터 목적지까지 갈떄 중간에 지나갈수있는 최대의 hope 수 ( router 수)
- protocol ( 8 bits ) field : 네트워크 계층에서 수신한 값을 어떤 프로토콜을 사용하였는지 판단 ( TCP /UDP )
- header checksum ( 8 bits ) : 비트에서 오류가 생겼을떄 체크 ( Check errors )
- flags (3 bits) : used in fragmentation - DF / MF ( Don't fragment / More fragment )
- Source address : The IP address of source (user privacy 포함가능)
- Destination address : The IP address of destination (user privacy 포함가능)
첫번쨰 4필드 : 버전 필드 / 두번쨰 4필드 : 헤더의 길이
- Header
-> 기본 20 bytes / 늘어날수있는 최대 40 bytes -> 최대 60 bytes
-> 암호화가 이루어지지않음 ( incapsulation X / 항상 오픈되어있음 )
-payload
상위계층에서 내려온 정보가 이곳으로 들어옴
-> 이 정보들을 네트워크 내에서 처리하기위한 incapsulation 과정을 거치는 곳이 Header 이다.
Example 7.1
An IP packet has arrived with the first 8 bit shown :
01000010
The receiver discards the packet. Why ?
풀이 : 첫번쨰 4필드 0100 -> 버전 필드 : 0100 = 10진수변환 -> '4' : IPv4 라는것을 확인가능
( IPv4 헤더의 최소사이즈 : 20~ 60 bytes )
두번쨰 4필드 0010 = 10진수변환 -> 2 * 4 = 8 bytes
정답 :
-> 헤더의 최소사이즈(20)에 미달되는 값이 들어옴. -> 패킷중간에 오류가 생겨서 미달값이 생김 .-> 버림
Example 7.2
In an IP packet, the value of HLEN (Header Length) is 1000 in binary. How many byte of option are being carried by this packet?
풀이 : 헤더길이가 1000 -> 10진수변환 : 8 * (IPv4이므로 *4) : 헤더길이 = 32 bytes
-> 헤더길이의 최소값 : 20 bytes : 32(입력값) - 20(기본값) = 12 bytes 의 추가된 옵션을 가지고있음
Example 7.3
In an IP packet, the value of HLEN(Header Length) is 5 16 and the value of the total length field is 0028 16 . How many bytes of data are being carried by this packet ?
풀이
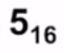

Header length = 5 * 4 (IPv4 이기때문) = 20 bytes
Total length = 2 * 16 + 8 : 40 bytes
-> 이 패킷의 실제 데이터 : 40 -20 = 20 bytes
- Fragmentation
datagram의 총 크기가 항상 MTU(Maximum Transfer Unit)보다 작아야한다 -> 그래야 분할이 이루어지지않는다.
Fragmentation = 데이터그램이 네트워크를 통과할수있도록 만들어주는것
DF (Don't Fragment) : 더이상 fragment 될것이 없음
MF (More Fragment) : 더 fragment 할것이 남음
-> 한번 fragmentation을 진행할경우마다 offset value가 바뀜( fragmentation의 시작점이 바뀜 )
-> bit 값은 워드단위이기 떄문에 : ex) 0000/8 = 0 - 1400/8 = 175 - 2800/8 = 350
Example 7.8
A packet with M bit of 0 has arrived. Is this first fragment, or a middle fragment? Do we know if the packet was fragment ?
풀이 : More Fragment 가 0 (더이상없음) 이니까, last segment 이다. (마지막)
더이상없음(=분할될것이 없음) 이니까, 애초에 Fragment가 아닐수도있다. 그렇게에 fragment가 아닐수도있다.
Example 7.9
A packet with offset of 100 has arrived. HLEN(Header Length) = 5 and the value of the total length field = 100. What is the number of the first byte and the last byte ?
풀이 : offset value : 100 : 8 * 100(total length field) = 800 bytes 부터 시작 ( offset 값은 각 fragment 시 시작값 )
total length = 100 bytes / HLEN = 5 * 4(IPv4) = 20 bytes
-> 실제 payload의 사이즈 : 80bytes (=실제 옵션데이터)
-> 800+80(추가옵션데이터값) : 첫 데이터 bytes : 800 ~ 마지막 데이터 bytes : 879 / 다음 시작 offset : 880 ~~>
- Options
TLV의 형태로 되어있다 : type / length / value
- No Operation Option(NO-OP) : 각 옵션을 구분하기위하여 앞이나 끝에 붙혀주는 옵션(구분자 역할) 여러개 사용가능
- End of Operation : last option을 나타냄 / 오직 1개의 End Option을 사용
- Record Route Option : 소스에서 도착지까지 가는 경로에 있는 거쳐가는 라우터의 정보를 기족하는 옵션 ( 실질적으로 패키지를 manage 하는 입장에서 유용 [ 현재 대부분 안쓰임 ]
-> 최대 9개의 라우터까지만 저장가능 : 이유는 ? -> 헤더의 최소사이즈가 20 , 60byte이기 떄문에 옵션을 가질수있는 최대 -> 40bytes 이며, IPv4의 주소는 32bit -> 4bytes 가 들어감(한라우터당) -> 4*9=36까지가능 : 옵션의 끝에 end of operation 옵션이 들어가기떄문에 9개 까지만 가능하다.
-> Pointer : 처음을 나타내주기 위한 offset
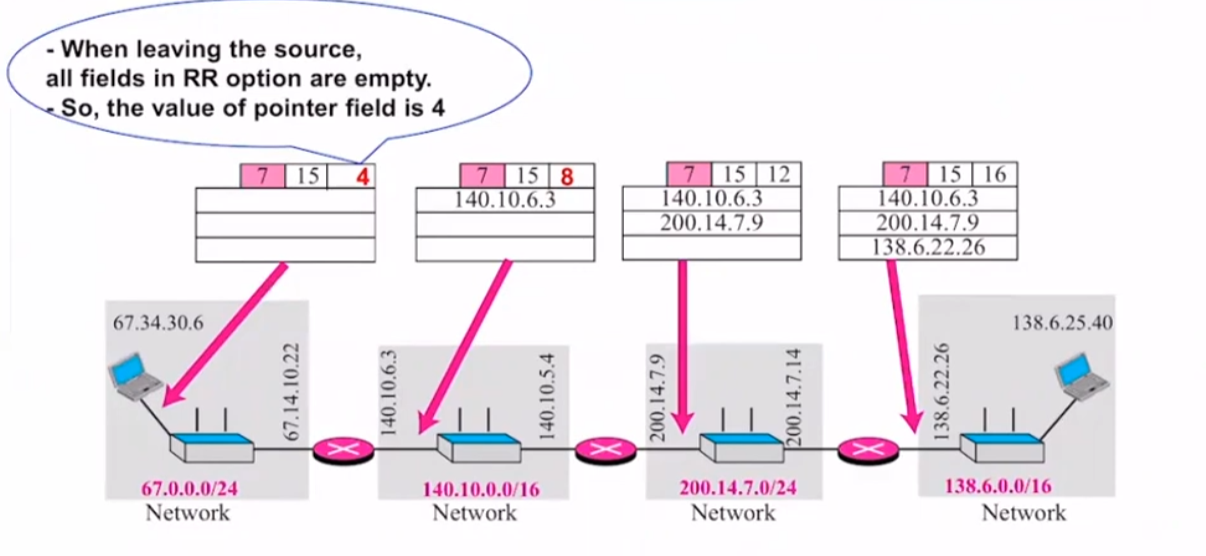
-> 처음 시작하는 포인터 시작값 : 4 -> 이후 하나의 주소 추가기록 : 4+4=8의 시작값 ~~ 12byte로 시작 ~~ 16 ~~>
-> 위 그림에서 저장되는 IP 주소값을 잘 보아야함 . : 거쳐간 라우터 패킷들의 값들을 확인 !
- Source-Route Option
정보를 암호화할떄 일반적으로는, Header를 제외한 payload만을 암호화한다. : transroute 사용
-> 소스노드가 루트를 결정하는것 (중간에 거쳐가야할 라우터를 지정)
-> Strict option : 엄격/내가 지정한 루트(라우터)를 반드시 거쳐야함 (보통 네트워크가 작은경우 사용)
-> Loose option : 내가 지정한 루트를 지나가기는 하는데 순서상 중간에 다른 노드가 껴도 상관없음 ] (대부분 글로벌 네트워크일떄 - 그나마 요즘 사용 )
Strict option과 Loose option의 차이 : 융통성없이 지정한것만 따름 : Strint option / 융통성있지 지절한부분 거치기만하면됨 : Loose option
<Source-Route option>
- Timestamp Option
라우터에서 datagram을 받아서 처리했을떄의 시간을 기록하는 옵션 ( msec 단위로 기록 )
flags : 0일때 -> 오직 시간만 기록
1일떄 -> 주소와 시간을 기록
3일떄 -> 옵션에서 주소가 발견되면 시간을 기록
-> 1 datagram 마다 사용을 해야하기 떄문에 라우터에게 너무 큰 부담을 주기에 잘사용하지않는다 .
Checksum
헤더의 비트오류를 체크하기 위해서 만들어놓은 비트
0 : 비트오류 X / 0이아닌값 : 비트오류
- ARP
IP-to-MACaddress mapping을 사용: IP-toMAC :내가 알고싶은 IP를 사용하는 device의 MAC주소를 알고자할떄 사용
-> IP 와 MAC주소에 대한 address mapping을 담당하는 프로토콜이다.
= 타겟의 ip주소를 알고있을떄, 타겟ip에 mapping 되는 mac주소를 알고자할떄
- ARP 계층상위치가 2.5 ( Network layer)인 이유 : ip datagram생성-> frame으로 incapsulation하기전에 arp 프로토콜을 호출 -> layer3작업 후 layer2작업전에 arp가 돌아가기떄문이다.
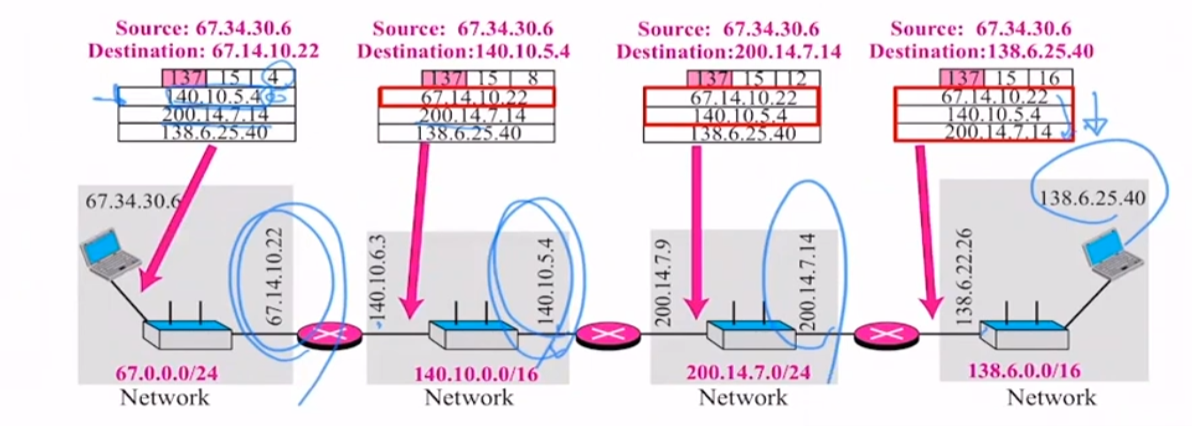
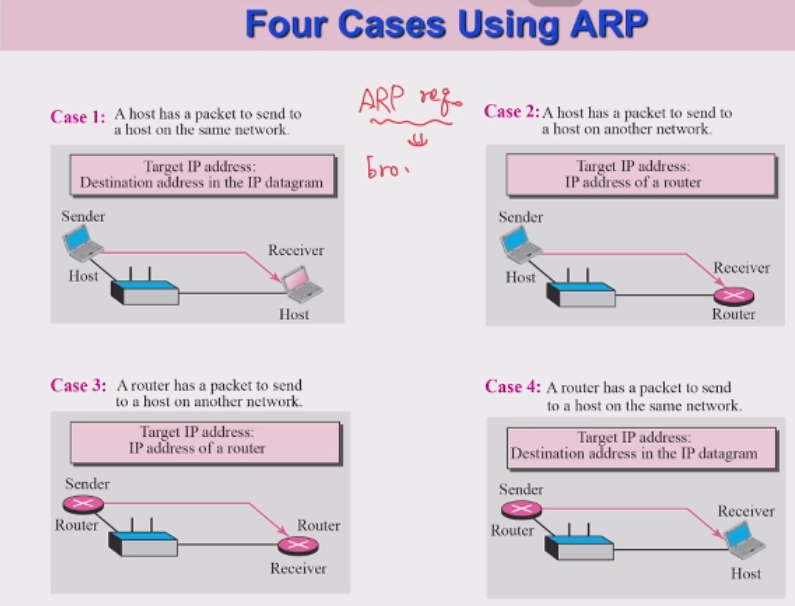
- ARP Protocol이 사용되는 4가지 환경
1 -> sender와 target(타겟)이 동일 네트워크에 존재할떄 (sender -> target)
2 -> sender가 호스트이고, 다른 네트워크로 타겟을 잡을때 (sender -> router1)
3 -> sender가 router(라우터) 일떄 (router1 -> router2) -> Next router(2)를 만들어서 포워딩 진행
4 -> sender가 router(라우터)이며, target(타겟)과 동일 네트워크에 존재할떄 (router2 -> target)

--> 최종 : target Node의 MAC주소를 정확하게 gathering .
자신의 네트워크와 동일하지 않은 타겟을 위해 라우터정보가 기록됨 (mapping table안에 기록)
-> 내가 다른 네트워크에 통신을 하려하면 현재 나의 mac주소가 시스템에 기록됨
- sender와 target(타겟) node가 동일 네트워크에 존재하는지 알수있는 방법
본인의 Network prefix값 = ip packet의 목적지 Network prefix -> 동일 네트워크.
본인의 Network prefix값 != ip packet의 목적지 Network prefix -> 동일x 네트워크.
- ARP 프로토콜 진행 순서
패킷생성-> 패킷헤더를 보면 수신자의 목적지ip주소와 소스ip주소 획득 -> 연관된 physical주소를 mapping 테이블에 lookup을 하여 mac주소를 획득 -> address mapping 테이블을 업데이트 -> 그 정보를 datalink로 전달
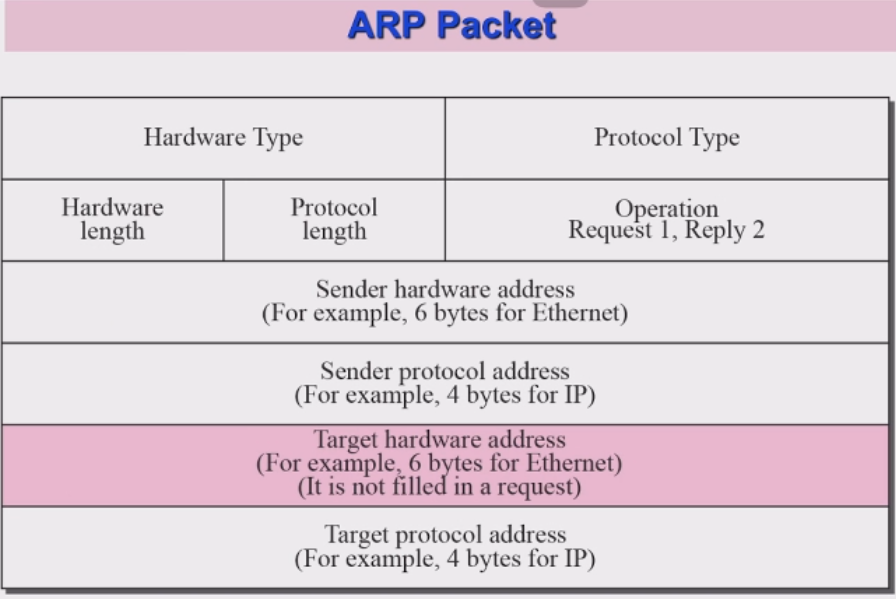
ARP Packet 구조
ARP Packet
- Hardware type(하드웨어 타입) : Ethernet : 1
- Protocol type(프로토콜 타입) : IPv4 : 0800 16
- Hardware length(하드웨어 길이) : physical length의 주소
- Protocol length(프로토콜 길이) : IP주소의 길이
- Operation : request(1) . reply(2)
ARP Packet -> 'IP datagram에 캡슐화'
ARP Operation 의 과정
1. sender가 목적의 ip주소를 알아야함
2. arp 를 호출 (request )
3. arp request를 만들기위해 목적의 ip주소를 가져옴 -> data link layer로 넘김
4. source(자신) , destination(수신자) 의 주소
5. arp request를 broadcast -> 모든 노드가 수신 -> arp request니까 arp 프로토콜 호출 , 실행
-> 정보x(응답x)시 폐기 , 자신의 mac주소에 대응(동일)하는 목적지 주소에 arp request 를 처리 ->arp reply 메세지 생성
-> unicast로 return -> ~~ -> 프레임이 encapsulation이 되도록 해줌
<두가지 mapping 방식이 존재>
- Static mapping (정적 매핑)
-> 정적으로 저장, 각각의 device에서 전부 저장 : 사용자의 ip주소(네트워크상의 identifier)를 알게됨
단점 : 인구가 많은경우에는 오버헤드가 매우 심하다.
- Dynamic mapping (동적 매핑)
-> 동적으로 저장, (실시간으로) : 위의 동적 ,오버헤드에 대한 해결책 -> 필요할떄만 사용
-> 마찬가지로 통신하고자 하는 상대방의 ip주소를 알게됨 / ARP 프로토콜 사용 / RARP 프로토콜 (현재사용 x)
RARP 프로토콜을 안쓰는이유 : ip주소가 글로벌 스탠다드가 됐기때문에, 기본으로 mac주소를 쓰지않아서.
ARP프로토콜이 필요한 이유 : 해당하는 device에 보낼떄마다 필수적이다. ip에 대한 mac주소에 대한 mapping을 알아야함. -> packet을만들고 destination , source 주소가 들어가는데 frame header밖에 못만든다. -> arp 프로토콜 필요
-> arp를 통해서 목적지의 mac주소를 획득할수있기때문이다. (기능적으로 심플)
[ ARP프로토콜의 시작 : 전송하려는 IP datagram의 packet , 수신자의 ip주소를 알고있을떄 시작 ]
frame으로 만드려면 반드시 사용자의 source MAC 과 수신자의 MAC주소( Physical address)를 알아야한다.
- Logical address ( == IP address )
-> 라우팅과 포워딩을 위해 사용 / globally 사용 / 32bit의 주소길이 / 식별자로서의 역할 / 네트워크 디바이스들이 ㅅ로의 식별자가 되는 역할을 하게해줌.
- Physical address ( ==MAC address )
-> one hop / device -device / hardware에 implement / 48 bits
Example 8.1
sender와 target이 동일 네트워크에 있다는것을 아는 방법 : 32bit의 IPv4 프로토콜 / ethernet / ~ 등 네트워ㅓ크 환경 이 동일
Proxy ARP
-> 장점 : 내가 request를 보냈을떄 reply가 빠름
-> 자신의 arp address mapping table을 보고 관련된 정보가 있는 node가 대신해서 보내주는것
--> 잘안쓰임
- ICMP
IP Protocol이 error-reporting 에 대한 기능을 가지고있지않기에, 이를 보완하기위해 만들어짐
-> 에러상황 발생시 : original sender에 전송 ( 데이터를 최초로 발생시킨 부분으로 )
-> 3.5 layer 에 존재 : incapsulation 해서 network layer로 내려갈떄 ip header가 붙기전에 transport layer에는 port num 과 ip address 주소가 있어야 가능한데 그 사이에서 icmp가 port num과 ip address를 같이 가져오기떄문
ICMP는 IP헤더 앞에 따로 자신의 헤더를 붙인다. 4계층에는 속하지 않지만 3계층 프로토콜의 역할을 도우면서 헤더를 붙일 수 있기 때문에 3.5 계층 정도로 취급하는 것이다. ICMP의 가장 대표적인 예시로 ping과 trace route이 있다.

ICMP Packet의 구성Message Format
8 byte 헤더 & data section이 변환적이다.
Error Message
- Destination unreachable
- Source quench : 소스노드에게 전송량을 낮추어달라고 하는것 ( =freeze) -> [ sender쪽에 slow-down 요구 ]
-> 수정 x / 정보전달만 -> 병목현상이 발생 ( 연구소나 테스트목적으로 주로쓰임 ) (traffic control)
- Time exceeded : TTL값이 0 이될경우 : 라우팅정보 오류, ~~ 등의 이유로 루프(LOOP)가 걸린경우 .
final이 fragment 필요 or 에러현상발생한 경우. -> 폐기후 알림
라우터에서 : code 0 / 목적지노드에서 : code 1
- Parameter problems : 헤더(header)에서의 오류 / pointer : 헤더내에서 오류위치를 표시하기위해 추가 -> 옵션 노드인경우 pointer 사용 x -> 그냥 0( null) 값
- Redirection (권고) : routing table을 업데이트 type : 5 / code 0-3 / IP address of the target router
Redirection attack : 모든 트래픽이 한곳으로 몰리게 -> 공격자는 바로 자신이 라우터 b라고 host a를 속이는 일을 해야합니다. 그것이 바로 icmp 리다이렉트 공격입니다. 공격이 성공하였다면 이제 host a는 특정 외부 사이트에 대해서는 무조건 라우터 b를 통해서 갈 것이고 그 라우터 b는 바로 공격자가 됩니다.
어디서 에러가 발생하는지 알기위해 -> session identifier 필요 : source와 destination의 IP주소 / PORT넘버 *
TCP Segment =>
IP header -뒤에 transport hearder 따라옴( 이안에*) : 이를 통해 수신된 에러메세지가 어떤 세션과 연관이 있는지 구분이 가능하다.
왜 8byte의 정보(데이터)가 들어가는지 ? -> port넘버와 sequence넘버가 Header안에 들어가게된다.
국내에서 ICMP를 차단하는이유 -> ICMP 가 공격으로 사용되는 사례가 많아서
Query Message :
네트워크 상황에 분석을 하기위한 용도로 발생시킴 .
- Echo request & reply : 두개의 pair로 구성됨 : host. router 모두 전송가능 < ping . >
- Timestamp request & reply : 왕복하는 전송시간값 출력 -> 네트워크의 상태,시간값 수정가능
-> 두 기기의 시간을 동기화 해줌 / 32bit 값을 가지고있음

타임스탬프 Round-trip 계산법
Original timestamp field : echo request가 출발할떄 시간값
Recieve timestamp field : 초기값이 0이고 리시버가 echo를 받았을떄 시간값
transmit timestamp field : 내부적으로 처리후 timestamp reply를 보낼때의 시간값
Transport layer -> TCP / UDP
TCP 와 UDP 의 가장 큰 차이점
TCP : Connection oriented , reliable(신뢰성) delivery -> numbering system ( udp는없음)
UDP : Connectionless , unreliable -> sequence num, ack 없음 ( 동작간단, 심플 ) -> 속도가 빠름 ( 유용성이높음 -> 이거 하나떄문에 조금 사용 ) / 신뢰성있는 데이터 전송이 어려움 / checksum 만을 제공 이외에 에러체크하는 기능이 없음
-> tcp 프로토콜이 너무 헤비 하니까 가벼워서 사용하는것이 그나마 이유
udp 제공 -> port num / application process id
TCP : numbering system
/ Flow Control : 전송량 제어
/ Error Control : segment 손실-> 재전송 : 신뢰성 있는 전송
/ Congestion Control : 혼잡상황 -> 전송량 조절
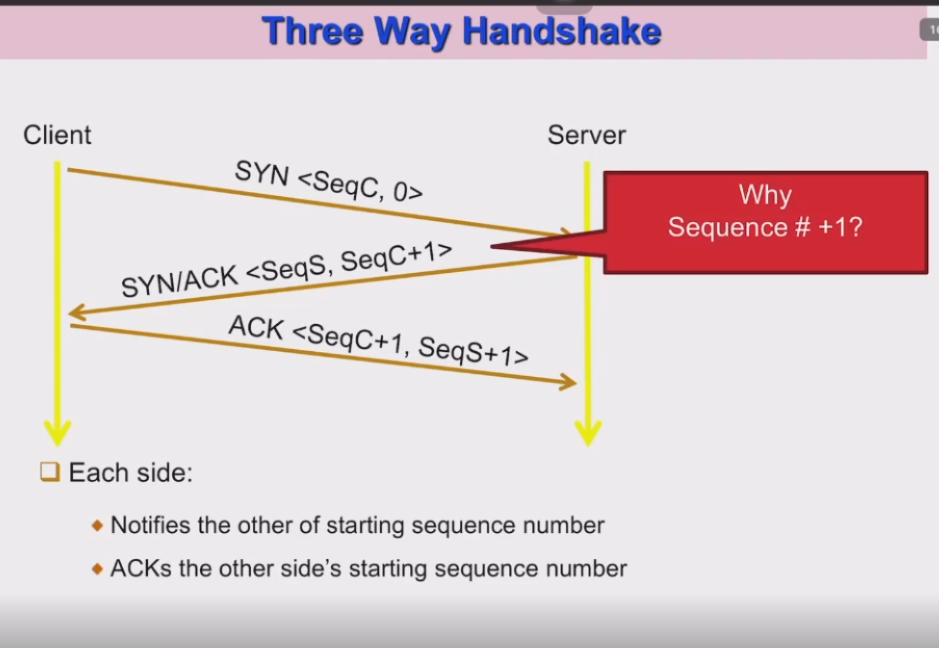
Numbering System 구조 : TCP 에서는 ACK 1을 받았으면 1을 다시 보내줘야할것같지만, 2를 보내줌. (next byte값)
--> ack number의 값은 그 다음 byte의 tcp 시작값과 같다 : 1일경우 2를 보내줌
Segment : 기존의 메세지 앞에 TCP header를 붙힌것
-three way handshake


'TCP-IP 프로토콜' 카테고리의 다른 글
| Cryptography - Symmetric key [ 네트워크 보안 ] (0) | 2021.10.07 |
|---|---|
| CIA Triad [ 네트워크 보안 ] (0) | 2021.10.07 |
| TCP / IP 프로토콜 [ TCP / UDP ] (0) | 2021.06.14 |
| TCP / IP 프로토콜 [ ICMP (Internet Control Message Protocol ] (0) | 2021.06.14 |
| TCP / IP 프로토콜 [ ARP (Address Resolution Protocol) ] (0) | 2021.06.14 |



